

#18740 closed defect (fixed)
U+025B (LATIN SMALL LETTER OPEN E) incorrectly reported as a bad character.
| Reported by: | Owned by: | team | |
|---|---|---|---|
| Priority: | normal | Milestone: | 20.03 |
| Component: | Core validator | Version: | |
| Keywords: | unicode | Cc: | Don-vip |
Description
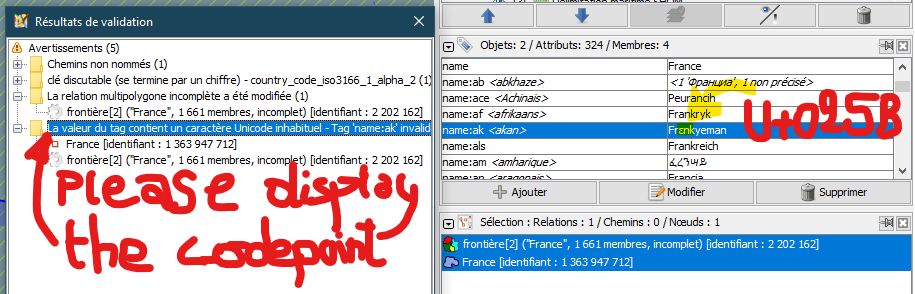
The *correct* tag "name:ak"="Frɛnkyeman" incorrectly reports that the character "ɛ" (U+025B LATIN SMALL LETTER OPEN E) is "unusual".
It is a standard part of several African Latin alphabets (including in Akan here). Not to be confused with a Greek small letter epsilon, even if it originates from it and was first defined for use as an IPA symbol, it is now part of the African alphabets.
Note: the letter is dual cased, its capital letter is U+0190.
Can you fix it to remove this incorrect statement in JOSM validator and add the pair U+025B/U+0190 as valid ?
How do you detect "unusual" characters ? Is it based on CLDR data but you lack data for Akan (ISO 639 language code "ak").
If you don't have alphabet data for a specific language, at least you could still check that the script properties are compatible (here the label is fully written in the Latin alphabet, there's no mix of any Greek letter)
Note also that some labels in OSM are created for the IPA trancriptions (with a specific BCP 47 language subtag "-fonipa") for which the leading language should not matter, but the set of valid IPA letters should be checked, along with their combining diacritics, plus a few punctuations or spaces, and some regular punctuations like the "colon" ":" is also invalid and confused with a specific IPA symbol)
Attachments (2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (27)
comment:1 by , 6 years ago
by , 6 years ago
| Attachment: | Annotation 2020-02-20 173133.png added |
|---|
follow-up: 4 comment:2 by , 6 years ago
Note: the screenshot shows the problem and suggests changing the message reported by JOSM validator: it should display the Unicode code point (in the standard form U+NNNN with 4 to 6 uppercase hexadecimal digits) at end of the message, for proper identification (and possibly the character name if you have the Unicode character database; if it is non combining with the general category "W*", "P*" "S*", "N*", "L*", the literal character should be displayed between quotation marks, like "‹ɛ›" here)
comment:3 by , 6 years ago
| Cc: | added |
|---|---|
| Keywords: | unicode added |
Replying to verdyp@…:
How do you detect "unusual" characters ?
Based on the Unicode blocks, see https://josm.openstreetmap.de/browser/josm/trunk/src/org/openstreetmap/josm/data/validation/tests/TagChecker.java#L456 for the code. At the moment, all UnicodeBlock.IPA_EXTENSIONS are reported except for U+0259.
The validator check has been introduced via #17546.
comment:4 by , 6 years ago
comment:5 by , 6 years ago
the "IPA extensions" block was not introduced just for IPA. IPA uses only the standard Latin script (but only its lowercase letters as phonetic symbols). And the letters "open e" and "open o" are common in African languages, and have case pairs (unlike a few IPA extensions like /g/, which are derived letter forms).
The block in which they were encoded is not relevant.
comment:6 by , 6 years ago
- U+0254 (Latin small letter open o) is paired with the capital letter U+0186 in several African languages
- U+0259 (Latin small letter schwa) is paired with the capital letter U+018F in Azeri
- U+025B (Latin small letter open e) is paired with the capital letter U+0190 in several African languages
So you have at least 5 missing exceptions in this code:
private static boolean isAllowedPhoneticCharacter(String key, int c) { return c == 0x0259 // U+0259 is used as a standard character in azerbaidjani || (key.endsWith("ref") && 0x1D2C <= c && c <= 0x1D42); // allow uppercase superscript latin characters in *ref tags }
comment:8 by , 6 years ago
| Milestone: | → 20.02 |
|---|
comment:9 by , 6 years ago
There are other Latin letters incorrectly signaled only because they were allocated in the "Latin - Phonetic extensions" block (once again these are lowercase letters, many of them are paired with an uppercase letter, and are used in actual orthographies).
Example:
- U+014B Latin small letter eng <ŋ> / U+014A Latin capital letter Eng <Ŋ> (used in Sami, and several North-European, Uralic and Turkic languages)
Once again checking the presence of IPA symbols (which are actually small Latin letters) is not an error. It would be however more useful:
- to check the encoding of "*_fonipa" transcriptions to make sure they contain only letters in the IPA subset (which has a well defined standard).
- ALL letters in the Phonetic extension block that have a casing pair are NOT used only for Phonetic, so they are used for actual languages written in the Latin script. The Unicode ncoding block is still NOT relevant at all. Better use the character properties but not this one (Unicode blocks are mostly defined for version tracking and the IPA extension blocks were added only to facilitate the creation of fonts containing all phonetic symbols, but many of them were also encoded at the same time with associated capital letters.
In rare cases the capital letters were encoded in later version of Unicode (in that case the casing pair is not part of the basic UCD properties, because they are stabilized, but are still added in tailored casing pairs for specific languages using them, e.g.
- the specific casing pairs for i and j distinguishing dotted and undotted letters in Turkic languages, unlike other Latin-written languages where i and j are "soft-dotted".
- the specific casing pair for sharp s in German (whose capital version was added late)...
- all special caising pairs are part of the UCD, but in separate properties for specific languages; they are also in CLDR data (in CLDR, the root locale only uses the standard simple case pairs but that locale is not a language; actual languages are NOT restricted to use only the simple casing pairs stabilized in the base UCD file and can override these pairs and change them over time to follow newer or older ortographic recommendations and practices for specific languages).
More genrally the assumotion in https://josm.openstreetmap.de/browser/josm/trunk/src/org/openstreetmap/josm/data/validation/tests/TagChecker.java#L456
is wrong.
as well it checks for a non-standard suffix in a tag to detect phonetic transcriptions, instead of using the *standard* BCP47 subtag for IPA phonetic transcriptions: "-fonipa" added to the base language tag, without any colun (I would not recommand using OSM subtags with colon separator, this may be an old practive before people got aware of the BCP47 registered subtag which is more precise...)
comment:10 by , 6 years ago
If you want a test case:
- "name:kbp"="Hayɩ Kiŋ Teŋgu" (for "name:en="North Sea") should also be valid, not signaled becaise of the "ŋ" letter, part of the alphabet for Kabye, a common African language, in the Kabyle subgroup, spoken and written in Algeria, Tunisia, Morocco, Lybia, and Chad (even if it's a minorty language, in countries where Arabic is official and French or English are also commonly used de facto without official status).
comment:11 by , 6 years ago
| Resolution: | fixed |
|---|---|
| Status: | closed → reopened |
comment:12 by , 6 years ago
Given you've reopened this, it would be good to check the CLDR data for alphabets in use in supported languages, and compile a list of Latin letters encoded in IPA paired with uppercase letters. There are probably others (I can think about Latin letter alpha for example, but I did not find obvious occurences).
Another way would be to check the list of country names that are likely to be translated in many languages, including minority/regional ones, notably large ones with many local languages like USA, Russia, China, Cameroon, India), or important features (including capital cities). Wikidata also provides many of these names.
Then load their names encoded in OSM, lookup their language code, check CLDR for their alphabets, and check they pass this check in the validator.
The assumption on Unicode character blocks used by IPA remains incorrect (if you've integrated ICU4J, CLDR data and better character properties may be useful than making custom "if" for some exceptions and not others, even if this solves some problems temporarily).
And it would be more useful to check that there are no confusion between Latin and Cyrillic or Greek letters, notably confusable ones like "a" and "o" (and their capital letters) inserted by error in mixed script names because they are more likely to be typos, not easy to detect and prone to such confusion, due to the way keyboards for Cyrillic or Greek are made and used. (note that JOSM alsone may not check everything, there are other QA tools allowing such detection later, like Osmose, which can check the correct encoding for names in Russian, Ukrainian, Bulgarian, Serbian and Greek).
Thanks anyway for these fixes and for reopening the issue.
comment:13 by , 6 years ago
| Milestone: | 20.02 → 20.03 |
|---|
comment:14 by , 6 years ago
- Reopen for "name:bm"="Esipaɲi". This is the standard name for Spain, translated in Bambara [ISO 639: bm] (a national language of Mali, also spoken by minorities in a large surrounding region, with ~14 million speakers in Mali, Burkina Faso, Côte d'Ivoire, and Guinea).
It uses the lowercase Latin letter "ɲ" (U+0272), whose capital is "Ɲ" (U+019D). There's also the letter "ŋ/Ŋ" (U+019E/U+0273).
These two letters are part of the alphabet of Bambara, standardized in Mali since 1982:
A B C D E Ɛ F G H I J K L M N Ɲ Ŋ O Ɔ P R S T U W Y Z
a b c d e ɛ f g h i j k l m n ɲ ŋ o ɔ p r s t u w y z
These two letters are also used for other Mandingue languages in the same region and written with a Latin alphabet, such as:
- Dioula [ISO 639: dyu] (spoken by ~20 millions in Côte d'Ivoire, Burkina Faso, Mali, Guinea, and Ghana)
A B C D E Ɛ F G H I J K L M N Ɲ Ŋ O Ɔ P R S T U V W Y Z
a b c d e ɛ f g h i j k l m n ɲ ŋ o ɔ p r s t u v w y z
- Mandinka [ISO 639: mnk] (spoken in Senegal and Gambia): a b c d e f g h i j k l m n ñ ŋ o p r s t u w y A B C D E F G H I J K L M N Ñ Ŋ O P R S T U W Y
- Eastern Maninkakan [ISO 639: emk] (spoken in Guinea, Mali, Gambia, Sierra Leone, Liberia, and Côte d'Ivoire)...
comment:15 by , 6 years ago
Note that "ɲ/Ɲ" is frequently replaced by "ñ/Ñ" in Bambara (like it is in Dioula) even if it's not the standard alphabet of 1982. "ñ/Ñ" may then be found in the value of "alt_name[:bm]=*" tags and probably in "name[:bm]=*", notably because it is easy to type with a French keyboard (French is also a major language in Mali, and Bambara-French duial speakers are not uncommon there (and in the Malian diaspora living in France, Belgium, Switzerland or other countries where French is official).
May be JOSM could suggest the standard orthographies to replace some characters that are currently accepted without warning but that are not part of the language standard (see CLDR data about standard alphabets)
comment:16 by , 6 years ago
The standard Bambara letter "ŋ/Ŋ" may also be alternatively written as "ny/NY", and the standard Bambara letter "ŋ/Ŋ" may also be alternatively written as "ng/NG", for the same reason (or even in official documents such as identity cards and passports that frequently drop the diacritics and alternate form letters, and then will fallback to use basic Latin digrams)
comment:17 by , 6 years ago
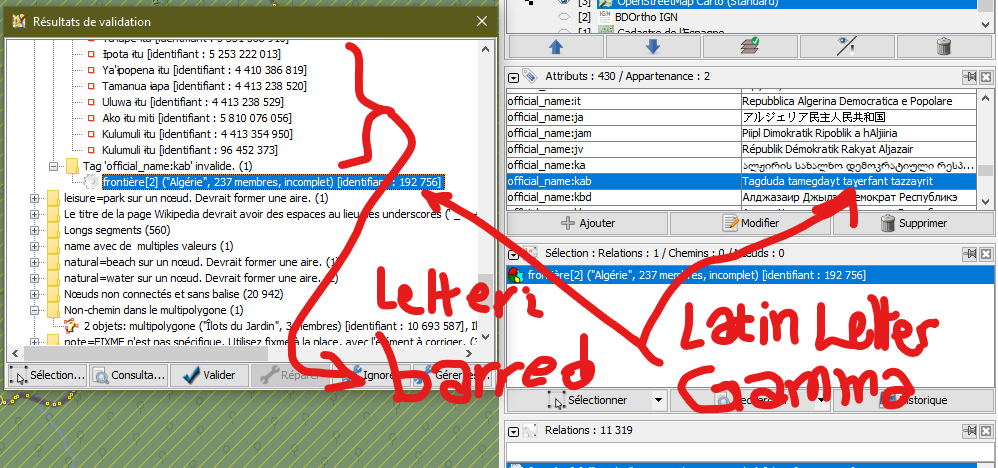
There's another pair of Latin letters used in actual language and signaled
"name:oym"="Wɨlapaleya Ɨtu" ("name:fr"="Saut Oulapaleya"):
This is the toponym of a waterfall in French Guiana, with a name in Oymara, a local amerindian language having distinctive vowels needing extra distinctive letter forms (the lowercase is initially borrowed from IPA, as generic combining diacritics have other use for writing tonality).
The letter pair "ɨ/Ɨ" (U+0268/U+0197) is the vowel i/I barred by an horizontal strike.
Oymara [ISO 639: oym] is spoken in large part of of South America, notably in Bolivia and Peru (where it has official status), as well as Argentina, Chile, and some parts of Amazonian region (Venezuela, Suriname, Guyana, French Guiana, brasil)
There's also the Latin letter gamma "ɣ/Ɣ" (U+0263/U+0194) used in official names in kabyle [ISO 639: kab]
See the screenshot.
by , 6 years ago
| Attachment: | Latin letter i barred, Latin letter gamma.png added |
|---|
comment:18 by , 6 years ago
| Milestone: | 20.03 → 20.04 |
|---|
comment:19 by , 6 years ago
Current summary:
- "ɣ/Ɣ" (U+0263/U+0194)
- "ɨ/Ɨ" (U+0268/U+0197)
- "ɲ/Ɲ" (U+0272/U+019D)
- "ŋ/Ŋ" (U+0273/U+019E)
As you see, most "IPA symbols" (which are really lowercase Latin letters) are paired with a capital Latin letter: all those that are paired are used in actual languages. Very few IPA letters are for IPA use only (for now), and are specific standardized letter forms used to cancel the variation of Latin letter forms in normal orthography (like the variation of letters "a", "g" or "R" for creative, stylistic or artistic reasons, these variations being not permitted in standard IPA symbols which distinguish them and defines stricter shapes and metrics allowing standardized diacritics). Most of these lowercase letters were encoded at the same time as the paired capital letters, even if they were in separate blocks, IPA rarely invented these letters but made a selection in the Latin script, but sometimes IPA borrowed letters from Greek or Cyrillic (where they were already paired too with capitals), and some languages which were informally written with them started to be standardized in their romanized orthography using these paired letters as well (this is the case for the schwa and gamma letter), instead of using digrams, or combining diacritics on other basic letters.
comment:21 by , 6 years ago
| Milestone: | 20.04 → 20.03 |
|---|
Thank you for the summary in comment:19, very helpful and appreciated! :-)
comment:23 by , 6 years ago
Add:
- "ɯ/Ɯ" (U+026F/U+019C) Latin letter m mirrored (or "U in U" ligature; see https://fr.wikipedia.org/wiki/%C6%9C)
- "ʃ/Ʃ" (U+0283/U+01A9) Latin letter esh (used in the International African alphabet, the African Reference alphabet, the Dinka alphabet, the Pan-Nigerian alphabet)
- "ʊ/Ʊ" (U+028A/U+01B1) Latin letter upsilon (used the African Reference alphabet, and for various languages in Benin; see https://fr.wikipedia.org/wiki/%C6%B1 and https://fr.wikipedia.org/wiki/Alphabet_des_langues_nationales_(B%C3%A9nin))
comment:24 by , 6 years ago
Now with these additions, there's the problem of actual usage for specific languages.
<ldml/characters/exemplarCharacters> (base, plus type="auxiliary")
(Unfortunately, this is still not available in "charts" on the Unicode CLDR website, you have to look for them in individual LDML files at this path for each supported locale).
It's time to think about integrating the CLDR data about representative characters needed for languages. And provide a way to contribute to it, by submitting to CLDR some usable reports with relevant data (with statistics), collected in OSM and other integrable cartographic sources for local toponyms, or for brand names of shops/activities, etc.). Some existing QA tools may help generating these statistic reports (collected from tags like "name:*=*", "al_name:*=*"), helping to check/qualify them when they are unusual, but once validated, these reports containing statistics about valided tags would contribute to "auxiliaryCharacters" in CLDR for relevant languages (provided that OSM tags are properly indicating the applicable language).
See also:
https://github.com/unicode-org/cldr/tree/master/exemplars/main
(note that this is frequently indexed for now by ISO 639-3 codes, i.e. 3-letter codes, not 2-letter codes prefered in BCP47; there are some exceptions using BCP47 language tags for script variants; CLDR anyway also contains mappings from ISO 639-3 to BCP47 prefered codes; this list is draft supplemental data, not integrated in the main LDML data).
See also http://cldr.unicode.org/translation/transforms for the transliteration standards used in cartography (notably BGN and UNGEGN) which also defines common "alphabets" for this specific language-neutral use in cartography.
These characters may not all be part of the "base" set of examplar characters for relevant languages, but could be part of their "auxiliary" set (I've not checked if this was the case in existing data for examplarCharacter data in LDML data for all languages... If this is not the case, a bug report should be submitted to the CLDR TC about how to handle them; may be they could be part of the examplar characters for the "root" locale or a specific sublocale for international cartography)
As well, we should check if the supported "exemplar Characters" are supported by at least one cartographic transliteration standard (notably for toponyms, excluding brands), either as a source or target character of the translitteration. And then we could compile a new dataset for proper checking, instead of just allowing isolated characters independantly of languages (as this is done for now).
comment:25 by , 6 years ago
Note that "examplarCharacters" in CLDR core data are also used inside the CLDR project itself as a source for quality check for data submissions in various localizd entries (e.g. city names, countries/territories/division names, measurement units, date and numbers formatting). It is actively used in the CLDR Survey Tool. They could be used for exactly the same reasons in OSM data, i.e. quality check.
Note: standard IPA transcriptions ("name:<lang>-fonipa" when using BCP47 tags as suffixes for OSM tags) must use ONLY small Latin letters as base phonetic symbols (there should be no Greek or Cyrillic letters at all, and no capital letter).